A LangChain infrastructure benchmark by Nirvana Labs
 April Wong
April Wong
Storage tiers, task completion times, cost-per-task across platforms.
Why a cloud company is benchmarking an LLM framework
Most of our clients at Nirvana have been in Web3. Blockchain nodes, RPC, DEX router, analytics. Workloads that need serious I/O and don't stop ever. Our cloud and especially the storage (ABS) was built for that.
This year, we started getting POCs from teams beyond Web3. AI companies, database providers, analytics platforms (some with web3 clients too). Companies looking for infra that can keep up with vector databases, RAG pipelines, OLTP, OLAP, the kinds of workloads where storage performance actually shows up in the user experience.
That's what kicked off the investigation. We wanted to understand how AI workloads actually hit storage (does it even?), and whether anyone had already benchmarked it. It turned into a bigger research project than we expected.
We Googled "LangChain benchmark" and a few other things to see what's out there. Has anyone tested how different cloud storage tiers affect AI agent performance? How much can infra improve latency and throughput of HNSW?
What comes up: LLM accuracy benchmarks, framework-vs-framework comparisons, model eval datasets, parameter tuning studies, even AWS's own HNSW benchmark on pgvector (which varies the instance type, not the storage). All useful. All testing the same layer: the model, or the code wrapping it.
Nobody's testing the infrastructure underneath.
LangChain is the most popular open-source LLM framework. 138K GitHub stars, teams from startups to Fortune 500 shipping production agents on it. If we were going to benchmark AI workloads on our infrastructure, this was the framework to test against. Real agents, real storage I/O, real concurrent load. Not a synthetic read/write loop.
What the community already knows
The fundamentals are documented (and we confirmed some along the way):
- HNSW graph search is serial and disk-bound. Can't parallelize within a query. Known since 2024. DiskANN was built to solve it.
- Latency spikes at 1M+ vectors are expected. Qdrant's own docs address it.
- io2 is more consistent than gp3. AWS and Percona have both published on this.
- Qdrant's
inline_storage(v1.16) is a major improvement. This config alone can 10x performance. - Cold reads vs warm cache matters. If your dataset fits in RAM, you're benchmarking RAM.
The gap nobody's filled
Engineers on r/LangChain are finding that 75% of chain latency is overhead, not LLM work. Database calls, serialization, tool wait time. They're optimizing the code and getting 2-3x faster. Real gains. But nobody's asking whether the disk serving those calls could be faster too. And when we looked for anyone who'd tested the infrastructure layer, the actual disk under the agents, we found nothing:
- LangChain agent performance across storage tiers. Framework vs framework comparisons exist. Same framework on different infrastructure? Zero results.
- Task completion vs per-query latency. Every benchmark measures per-query p99. Nobody's asked which platform finishes 100,000 tasks faster when each task chains 6 ops across 3 services.
- Multi-tenant HNSW at scale across real platforms. 5 storage tiers, 50 Qdrant collections, 1,000 concurrent agents, all the data published. Doesn't exist.
- io2-64k vs io2-32k side-by-side. $1,472/month difference. Nobody's checked.
- Cost-per-task across tiers. Same workload, same code, same instance. Which platform finishes faster and at what cost? Couldn't find it.
What's next
This is why we've been benchmarking. The community has optimized the wrapper. We want to know what's happening underneath it.
9 tests. 5 storage platforms. Up to 1,000 concurrent agents. The investigation took longer than we expected, went in directions we didn't plan, and turned into a story of its own.
Full report and open-source repo dropping this week.
Nirvana: The High Performance Block Storage Cloud
High Performance Block Storage Cloud with High IOPS, powering blockchain, AI and real-time systems.
Learn more at Nirvana Labs
Nirvana Cloud | Pricing | Blog | Docs | Changelog | Twitter | Telegram | LinkedIn
Related Posts

Nirvana Kubernetes Service (NKS) Now Supports Auto-Scaling
NKS now supports auto-scaling, powered by Karpenter.
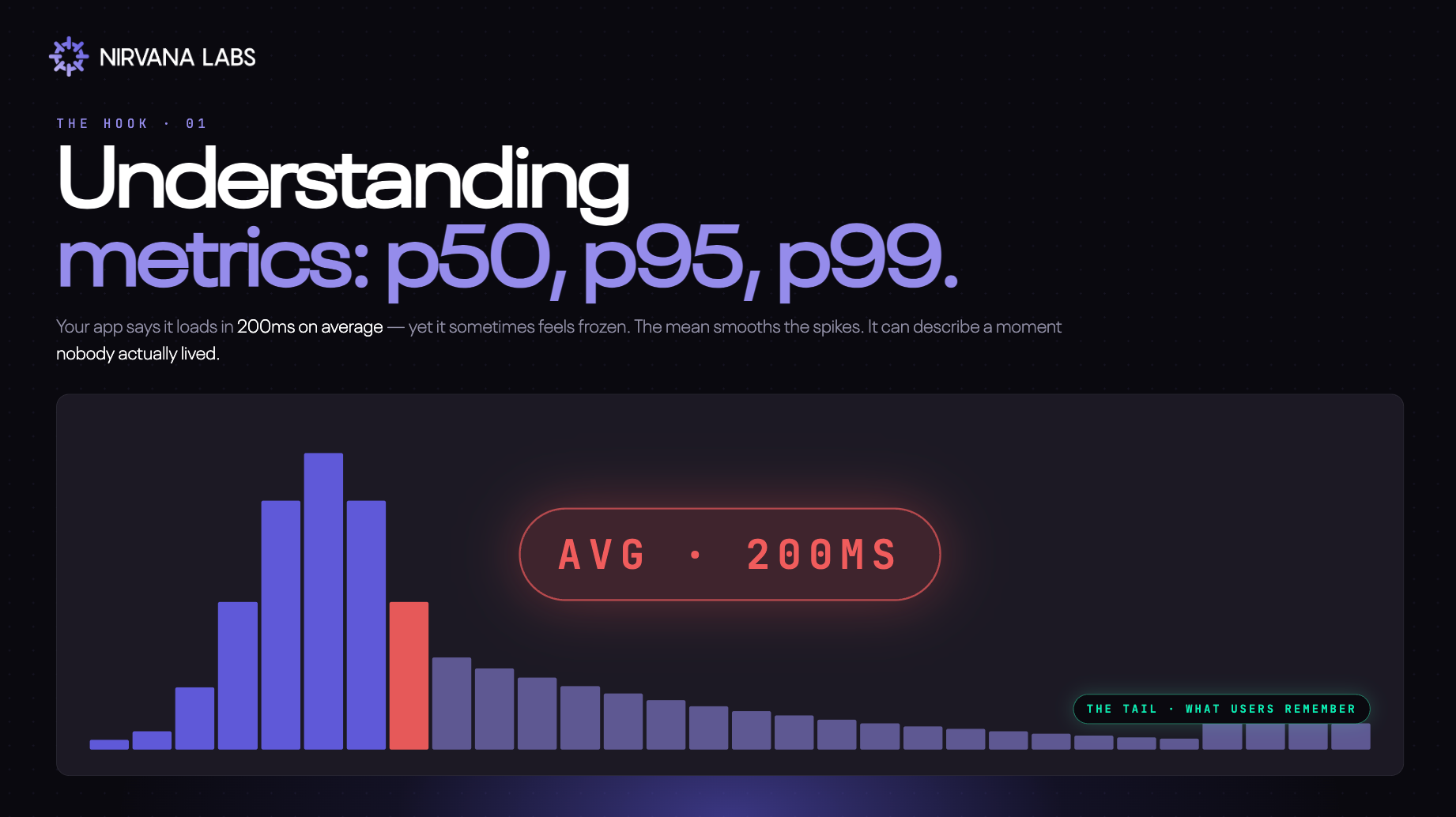
Understanding Latency Metrics: P90, P95, P99 Explained
Learn what p90, p95, and p99 latency mean

Nirvana Instance Types are live: Compute Families Built for Your Workload
Nirvana Instance Types are live: Compute Families Built for Your Workload
Powering AI, blockchain, and
databases
