

Another background piece to get out before the report drops, so we're on the same page of what LangChain is, how it works, where it hits the cloud, and which part exactly we are benchmarking.
What is LangChain
When you use ChatGPT or Claude, you type a question and get an answer. One API call. That's great for a conversation, but companies need more than that. They need the AI to search their documents, check a database, look up a customer record, take an action, and remember what happened.
That's why the industry has moved to agents. You're probably already using them. These don't just generate text. They reason, call tools, observe results, and keep going. The LLM is just the brain. The brain needs hands.

That's what LangChain does. It's the most popular open-source framework (138K GitHub stars) for connecting an LLM to real tools and data. Companies like Klarna, Uber, and Replit use it to build AI agents that don't just generate text. They reason about what to do, call tools, observe the results, and keep going until the job is done.
How the loop works
Before anything runs, LangChain bundles three components: the LLM (the brain, GPT-4, Claude, Llama), tools (functions the agent can call: search, query a database, send a message, run code), and a prompt (instructions for how to reason and when to stop).
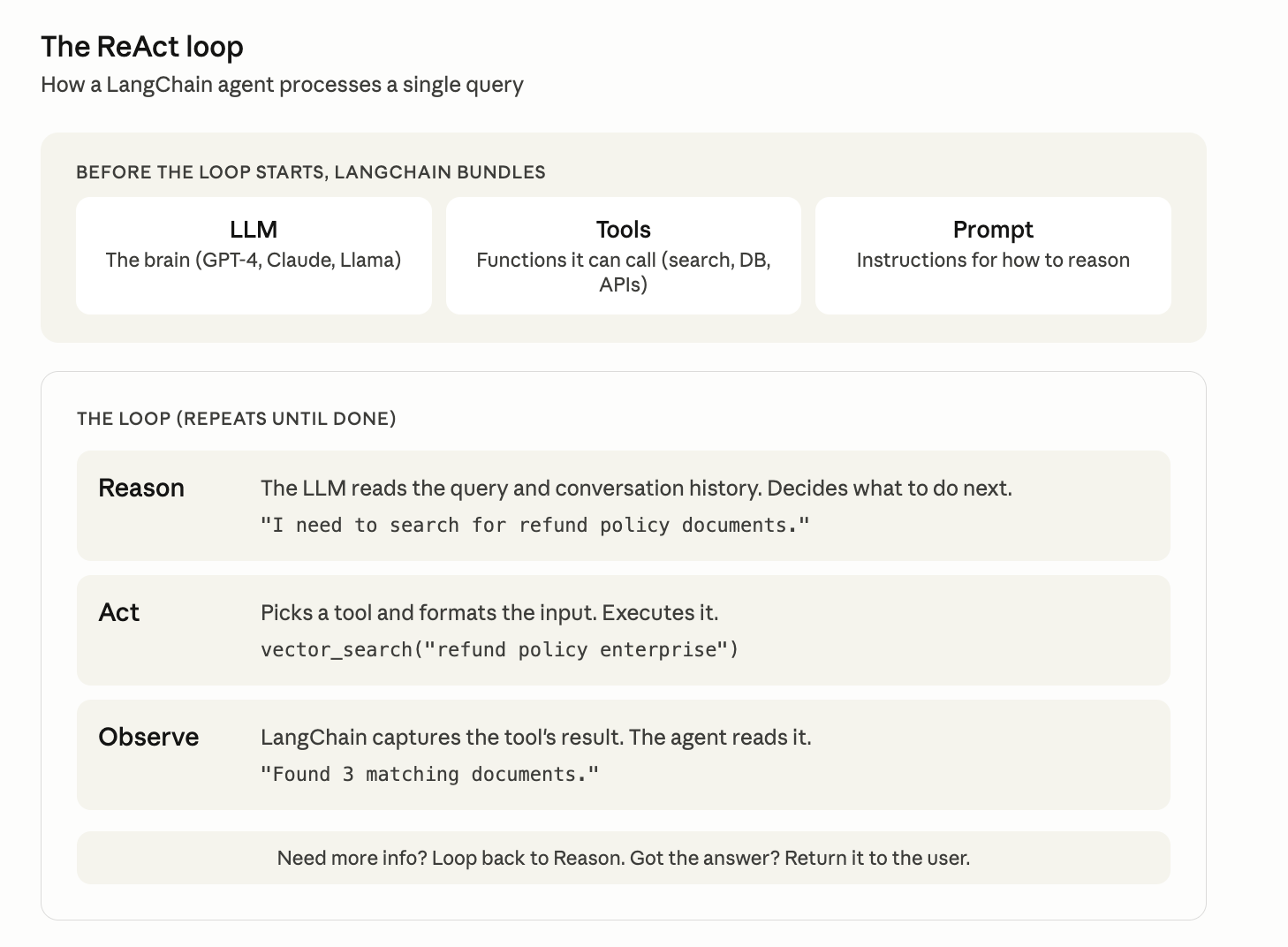
Once bundled, the ReAct loop starts. Reason, Act, Observe.
Reason. The agent reads the user's question and conversation history. The LLM thinks about what to do next. "I need to search for refund policy documents."
Act. This is where it gets interesting for us (Nirvana). The LLM picks a tool and formats the input. Call vector_search with "refund policy enterprise". That tool call doesn't stay inside the LLM. It leaves the model and hits a real application running on real infrastructure. A vector database that has to search millions of records. A cache layer that has to look up previous results. A checkpoint store that has to write the agent's state to disk. Every "act" is a storage operation happening on your VM.
Observe. LangChain captures the tool's result and feeds it back to the agent. "Found 3 documents about enterprise refund policies."
Then it loops. The agent reads the observation, decides if it has enough, and either acts again or returns the final answer. One query might loop 3, 5, 10 times. Each loop generates more tool calls, more disk I/O.
Where those tool calls land
Every time the agent acts, it hits a real application somewhere. There are Web and search (Tavily, SerpAPI, Brave). Workspace tools (Slack, Gmail, Google Drive, GitHub). API calls to third-party platforms. Developer tools (Docker, code sandboxes). Mostly compute-bound.
Then there's data and storage layer: Qdrant for vector search, Redis for caching and session state, Postgres for checkpoints and agent memory. These run on your VM. Every read and write hits the disk attached to your machine. And unlike the external API calls, the speed of these operations depends entirely on what storage is underneath them.

Every vector search walks an HNSW graph through hundreds of sequential disk reads. Every cache miss reads from disk. LangGraph writes a Postgres checkpoint at every single step of the agent loop, by design, for fault tolerance. A 10-step agent generates 10 Postgres writes per query per user.
Multiply by a few hundred concurrent users and the disk gets busy fast.
That's what we're benchmarking
We build cloud and awesome block storage. When we broke down how LangChain agents actually work, we realized the data and storage layer is the one place where what we build directly affects how fast agents finish work.
That's why a cloud company like Nirvana is benchmarking an LLM framework. It's not about the LLM. It's about the infra i.e. storage the LLM's tools run on and the workloads.
Report dropping soon.
This is a companion piece to our background research post. The full benchmark report and open-source repo are coming soon.
Nirvana: High Performance Block Storage Cloud
High Performance Block Storage Cloud with High IOPS, powering blockchain, AI and real-time systems.
Learn more at Nirvana Labs
Nirvana Cloud | Pricing | Blog | Docs | Changelog | Twitter | Telegram | LinkedIn
Related Posts

A LangChain infrastructure benchmark by Nirvana Labs
A LangChain infrastructure benchmark - storage tiers, task completion times, cost-per-task across platforms.

Benchmarking Block Storage: Nirvana ABS vs AWS EBS
Benchmarking Nirvana ABS vs AWS EBS gp3 and io2 with ClickBench and FIO TL;DR * Nirvana ABS is ~10–14× faster than AWS gp3 on cold-read analytical workloads * Nirvana ABS performs similarly to io2 (within 2× on ~98% of queries) * Nirvana ABS delivers ~20K sustained IOPS per VM in real mixed workloads * Nirvana ABS is ~18% cheaper than gp3 and ~8× cheaper than io2 → Strong default for analytics, blockchain, and data-heavy workloads * Check out the Benchmarking Report Block storage is

Case Study: Nirvana Labs & Goldsky
Client: Goldsky Industry: Blockchain Indexing & Blockchain Infrastructure Summary: Goldsky is a cutting-edge blockchain data company that offers various innovative web3 data solutions such as live-streamed data that empower numerous developers and businesses with comprehensive, real-time, and accurate blockchain data. Goldsky simplifies the intricate and resource intensive process of blockchain indexing, and providers this data to their customers with speed, precision, and white glove su
Powering AI, blockchain, and
databases
