CPUs are back: Why agentic AI needs more CPUs than GPUs, and what's next for cloud
 April Wong
April Wong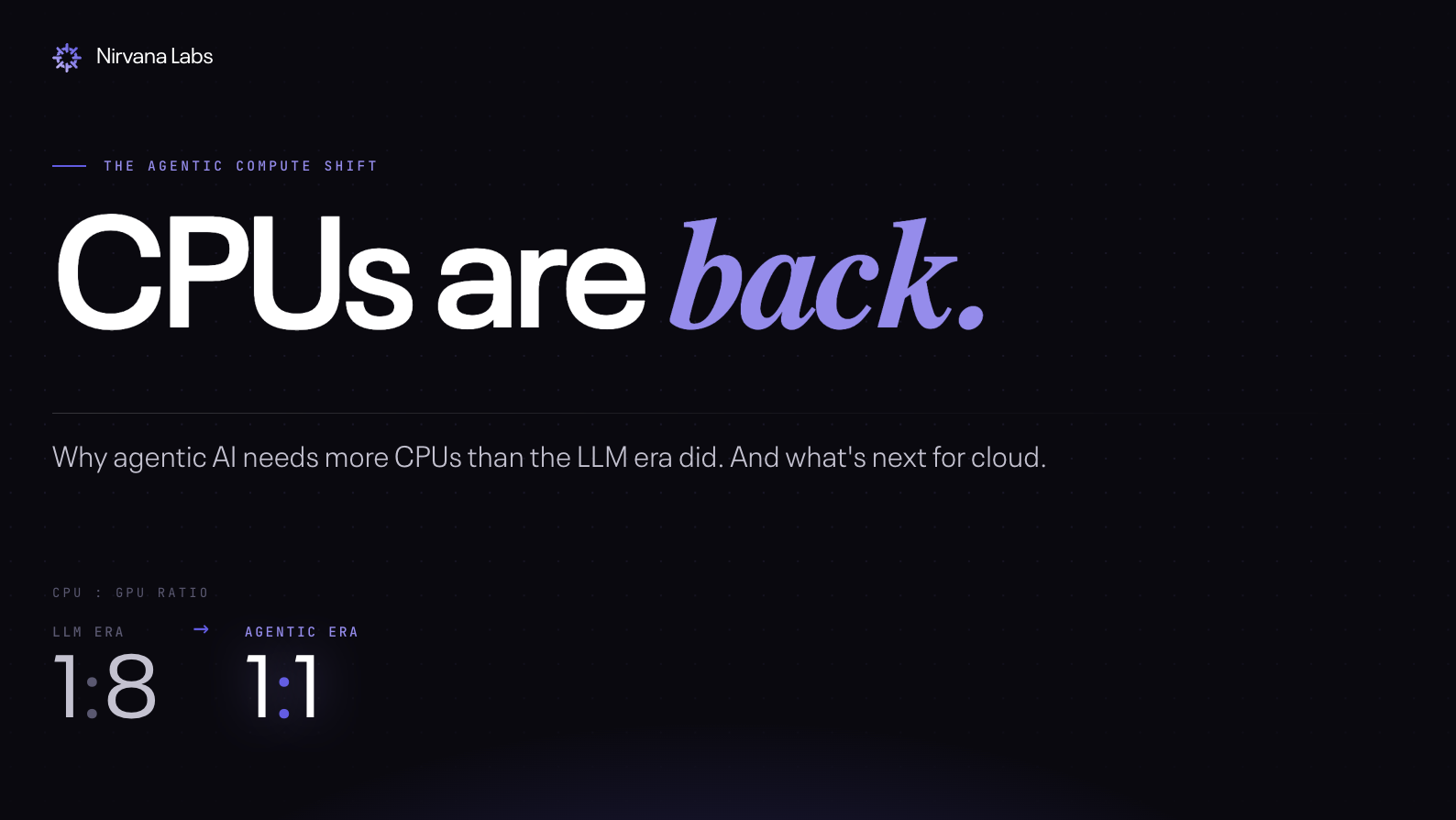
TLDR
- The CPU never went anywhere. It runs the OS, the network, the storage, and every part of an AI workload that isn't matrix math.
- The CPU:GPU ratio is shifting. The LLM era ran ~1 CPU per 8 GPUs per AI server. Intel says agentic AI tightens that toward 1:1.
- Agent loops are sequential: Plan, Act, Reflect, Revise. The GPU runs the model for one step; the CPU handles the other five.
- Arm projects 4× more CPU cores per gigawatt of AI data center in the agent era: ~30M cores/GW (LLM) to ~120M (agent).
- Server CPU ASPs are +27% in 1Q26 with ~6-month lead times. Intel says Xeon demand exceeds supply by a "meaningful" amount.
- The CPU is the bottleneck of the moment. Storage is next.
Saying "the CPUs are back" is misleading because CPU never went anywhere. No server can run without one; it runs the OS, the network, storage, and everything that isn't matrix math. GPUs accelerate specific workloads; they don't replace it.
For most of the AI era, the story has been about GPUs: Nvidia hit a roughly $5T market cap in April 2026 for a reason. But quietly, in the same month, the CPU made the loudest noise of the decade.
More signals from April 2026:
- Intel's stock rose ~90% in April after Q1 earnings showed Data Center & AI revenue +22% YoY to $5.05B. Its CEO publicly cited CPU:GPU ratios in AI data centers tightening from 1:8 toward 1:1 in agentic scenarios.
- Server CPU prices are up 10 to 20% since March, ASPs +27% in 1Q26, lead times around six months. Intel says Xeon demand exceeds supply by a "meaningful" amount.
- Even Nvidia is selling a standalone CPU now (the Vera, March 2026), and Arm shipped its first in-house data center CPU.
- AMD shares jumped 14% in a single session on an analyst upgrade tied to surging server CPU demand.
CPUs aren't a forgotten chip the AI cycle left behind. They've quietly moved back to the center of the conversation.
CPU vs GPU
What's the difference between CPU vs GPU and what do they do? CPUs are sequential: a few powerful cores optimized for low-latency, branchy logic where each step depends on the one before it. If A, then B; if not, do C. That's the essence of compute. GPUs are parallel: thousands of small, simple cores running the same operation on huge volumes of data at once. Think of a printing press.
Why did GPUs dominate the AI boom? Because modern AI is, at its core, matrix multiplication at massive scale. Training a frontier LLM means doing trillions of identical multiply-and-add operations across huge tensors: simple math, repeated at enormous scale. A CPU's few clever cores would grind through them sequentially over weeks; a GPU's thousands of cores chew through them in parallel in hours. The same applies to image generation, video models, and most of the workloads that defined 2022 to 2024: huge throughput, predictable math, no branching.
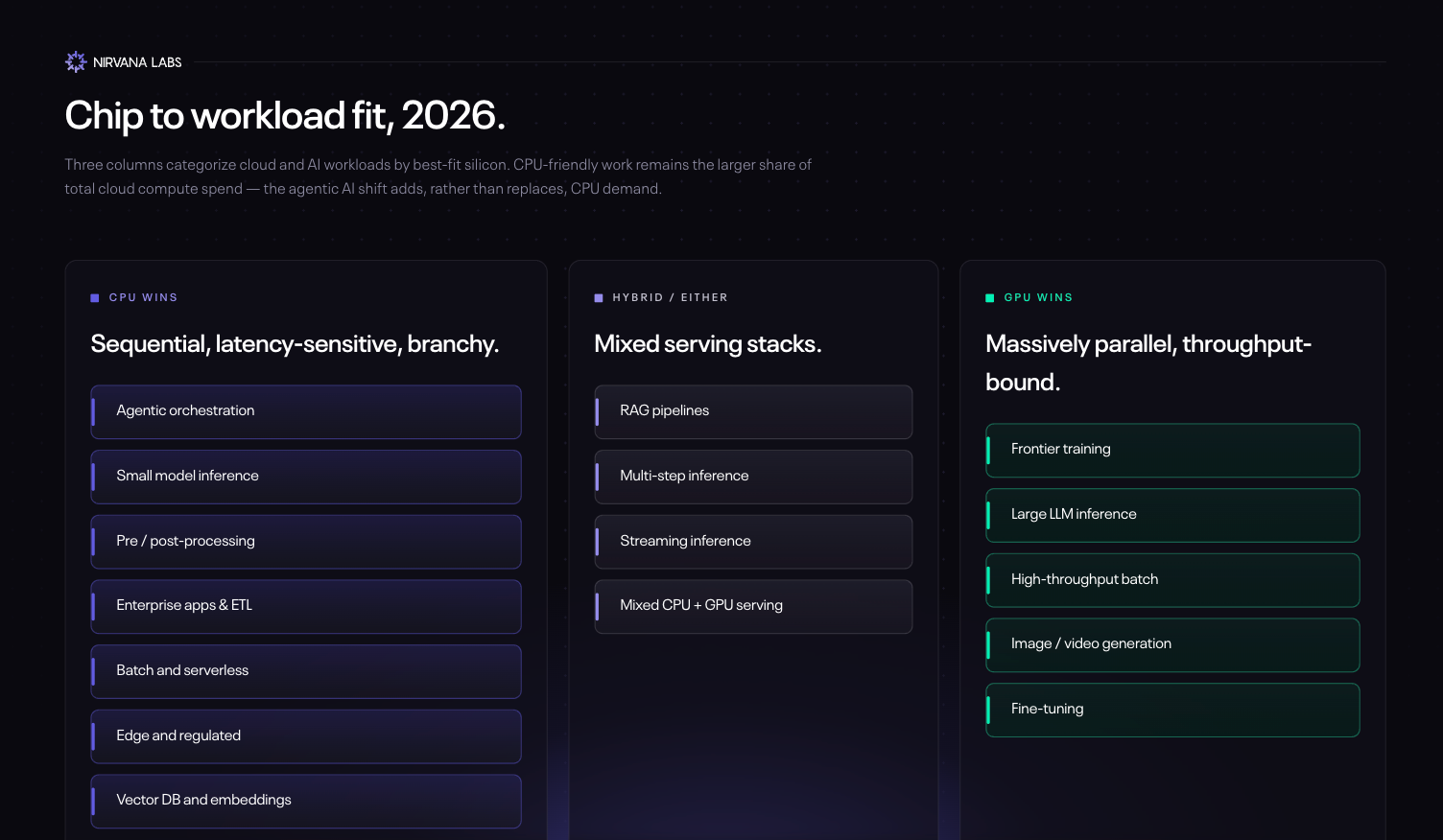
The plot twist: not every AI workload looks like that anymore.
From LLM to agentic AI
The shift in CPU demand isn't abstract. It maps directly to how AI workloads have evolved over the last three years.
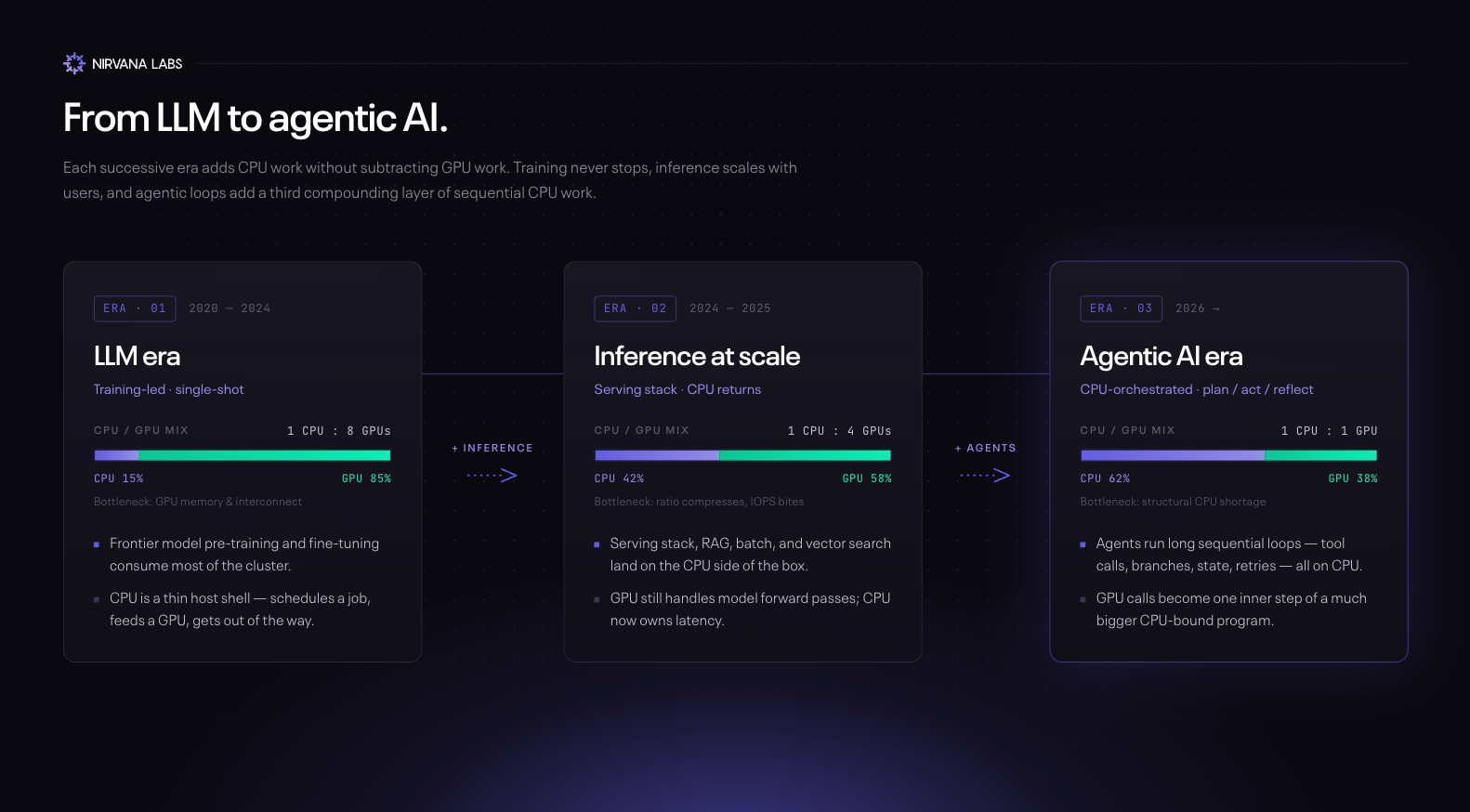
The LLM era (2020 to 2024). The dominant workload was training, plus simple single-shot inference: a question goes in, an answer comes out. Both are matrix-math-heavy and both fit GPUs perfectly. A typical AI server packed eight or more GPUs around a single CPU host, and the CPU's job was small: load weights, schedule batches, handle the network. Ratios of 1 CPU : 8 GPUs were standard.
The transition, inference at scale (2024 to 2025). As LLMs became products, inference grew from a niche to the dominant AI workload. Even simple inference has more CPU work than training: tokenization, batching, RAG retrieval, vector search, output validation, and the entire serving stack run on the CPU. Deloitte estimates inference will be roughly two-thirds of all AI compute in 2026, up from a third in 2023. The inference-optimized chip market is on track to exceed $50B this year. The CPU:GPU ratio started compressing.
The agentic AI era (2026+). Agents don't just answer. They plan, call tools, evaluate their own output, and retry when they fail. The whole loop, Plan → Act → Reflect → Revise, is sequential, branchy, and CPU-bound. The GPU runs the model; the CPU runs the agent. Intel cited a CPU:GPU ratio tightening from 1:8 toward 1:1 in agentic scenarios on its Q1 2026 earnings call, and TrendForce expects industry-wide ratios to land between 1:1 and 1:2. Arm goes further: AI data centers needed ~30M CPU cores per gigawatt in the LLM era; the agent era needs ~120M, a 4× structural increase in CPU demand.

Why agentic AI specifically needs CPUs
In an agentic system, the model is one component of a larger control loop. Most of that loop is sequential CPU work:
- Parsing the user's request and planning the next step
- Retrieving context — RAG, vector DB queries, memory lookups
- One LLM forward pass (the GPU's job)
- Parsing the model's output to extract the next tool call
- Executing the tool — API calls, code in a sandbox, file I/O, network requests
- Updating memory and deciding whether the goal is met or another loop is needed
That's one GPU step and five-plus CPU steps per iteration. The GPU literally sits idle while the CPU handles tool execution, waits on network responses, and parses results. Putting more GPUs on the problem doesn't help — you've just bought more idle silicon. What helps is more CPU. Production agent frameworks like LangGraph, AutoGen, and CrewAI are essentially CPU-orchestration engines that occasionally call out to a GPU.
What's next for cloud infrastructure
The CPU is the bottleneck of the moment. But bottlenecks shift fast in this cycle, and the cloud infra story rarely stays put for long. Three open questions worth watching:
Does the bottleneck move down the stack? Every AI layer is getting data-hungry: bigger training corpora, agent trajectories, self-correction journals, RAG, long-context windows. DRAM and SSD prices are up ~130% (Gartner); HBM stays constrained through 2027. The next "Graviton moment" may not be a CPU at all. It could be custom storage controllers, near-memory compute, or tiered-memory built for agent loops.
If superintelligence is the endgame, what does the rack look like? Today's hyperscaler architecture is essentially a denser 2010s data center. Self-improving systems imply GW-scale training jobs, global agent fleets behaving more like CDNs, and orchestration that spans continents. That points to liquid cooling as default, optical interconnect at every layer, and rack-level CPU/GPU/storage co-design. At what point does retrofitting stop being economic?
Can hyperscalers deliver leading performance, or just adequate performance at scale? AWS, Azure, and GCP optimize for breadth. Specialty AI clouds beat them on raw GPU benchmarks by serving only one workload, and that gap could widen as agentic AI demands tighter CPU↔GPU coupling and lower latency. Neo-clouds are riding it: CoreWeave, Crusoe, and Nebius are scaling fast on multi-year frontier-lab contracts that pay a premium for raw performance. The hyperscalers' counter is custom silicon (Graviton, Axion, Cobalt, Trainium, TPU, Maia) and tighter Nvidia partnerships. Does breadth let them invest fast enough, or does frontier compute live outside the big-three cloud next decade?
Bottom line
GPUs are the muscle and still indispensable — Nvidia's market cap reflects that. But the agentic AI cycle revealed what the GPU-only narrative obscured: the brain matters, and the LLM era under-built it. The CPU isn't replacing the GPU; the ratio is just snapping back - because the workloads we run in 2026 aren't the ones we built the racks for in 2023.
Nirvana: The High Performance Block Storage Cloud
High Performance Block Storage Cloud with High IOPS, powering blockchain, AI and real-time systems.
Learn more at Nirvana Labs
Nirvana Cloud | Pricing | Blog | Docs | Changelog | Twitter | Telegram | LinkedIn
Related Posts

Google Cloud Hyperdisk Balanced, Hyperdisk Balanced HA vs Nirvana Accelerated Block Storage (ABS)
Google Cloud (GCP) Hyperdisk Balanced, Hyperdisk Balanced HA vs Nirvana Accelerated Block Storage (ABS)

Go Multi-cloud and Build Redundancy today
If your infrastructure sits on AWS, your decentralization stops there.

Nirvana Labs Surpasses 60 Blockchain Networks Supported, Expands Customer Base to Over 50 Companies
Nirvana Labs, developers of the pioneering crypto-specific bare metal cloud platform, proudly announces a significant milestone: the support of over 60 blockchain networks and a rapidly expanding customer base that now exceeds 50 web3 companies.
Powering AI, blockchain, and
databases
